
Welcome to the fourth part of our implementation series of a BPMN model in (Java) code. We came a long way up and until the asynchronous reception of multiple, correlated messages. Although we left with previous part with some open technical details, which I will address in a future part, we will step back and look at our "integration architecture" and how BPMN can also help us to improve our service/API design. In particular, we will see how BPMN "recommends" us to use the Request Bundle Microservice API Pattern.
If you haven't read the previous parts, please read them first to get to know the context: Part 1, Part 2, Part 3.
Multi-Instance in BPMN and API Design
We have already covered some BPMN constructs on our journey so far: We have seen basic elements like tasks and events and certain types of those, we have seen pools and message-flows, and we have shortly seen our multi-instance activity.
And we will return to the multi-instance marker and its usefulness today! I have written about one problem type that can easily be spotted with multi-instance markers in a previous blog post but let's shortly reiterate what multi-instance is:
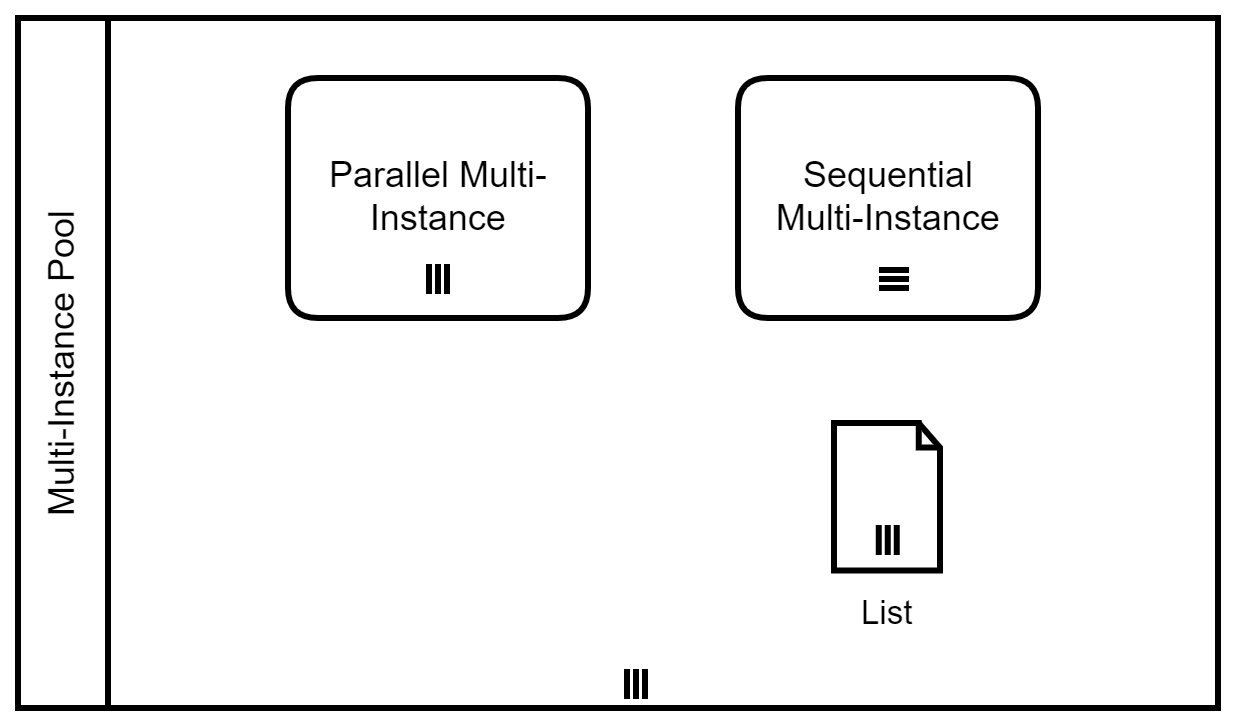
Activities, pools, and data objects in BPMN can be "multi-instance":
Multi-Instance Pool: A set of participants with the same role within this process, e.g., a set of suppliers from which I want to have a quote,Parallel Multi-Instance Activity: An activity (or any subtype like task, subprocess, ...) is repeated multiple times in parallel. Think of it as an parallel for-each loop.Sequential Multi-Instance Activity: An activity (or any subtype like task, subprocess, ...) is repeated multiple times in parallel. Think of it as a traditional for-each loop."Multi-Instance" Data Object: A list of data objects, e.g., orders etc.
In general, parallel running/existing things are denoted with three vertical lines, while sequentially executed ones are marked with three horizontal lines. How to remember this? Dieter Kähny, a colleague of mine in the Terravis project, told me a good mnemonic aid: Try to fit a p for parallel or an s for sequential onto the three lines, although I have to admit that for me the p(arallel) works much better than the s(equential):

The Rule
But let's talk about how this can help us. The general rule is very simple:
If the multi-instances of the message receiver (pool) and the the sender (sending activity or subprocess around it) do not match, it is highly likely to be a bad modeling decision, if not outright incorrect.If you have read my previous blog post about optimizations on the COVID quarantine process you remember that one major problem could be detected by this misalignment. We also have a misalignment this time, but it is inverted: We are sending multiple messages from a multi-instance subprocess to one single message receiver.
Why is this a problem? Because we are doing much more work than we are required to and thereby also creating problems with resource allocation! First of all, we don't need to implement logic to split a request in multiple ones if we can send all data to the same recipient in one go. By making multiple requests to the service/API provider we are utilizing more network capacity, waste time with latencies for initiating a connection, and resources for handling multiple connections. And because very often (like in the example below) the request is then parallelized (to have faster processing) we must
- allocate more resources on the process side,
- handle the increased the number of parallel requests on the provider side
- manage an indirect and hard to manage coupling of the degree of parallelization on the client side to the provider's resources (e.g., thread pool size, available memory, ...).
I think the first two problems are severe enough to avoid this problem but I want to stress c) a bit because in my opinion people underestimate it: Let's say the process has to manage a request, which is split into 10. Then the provider needs to provision 10 request threads for a each concurrent process instance if this scenario should be fully parallelized. So we get a multiplication of threads, which is bad enough, and won't scale necessarily. Let's suppose, there are 100 processes running in parallel then we need a provider thread pool of 1000 to handle all requests in parallel (and so on)! But there is another problem: If the process (or any other client for that matter) changes the strategy how to split the request and now splits one request into 20 requests instead of 10. This has a direct and huge impact on the load and consequently the sizing on the thread pool on the provider side, which is hard to track because there is no explicit dependency for it.
Request Bundle Pattern
How can we address this problem? We can send a large message containing all requests at once, and we get back a list of results for each individual request. This is described as a Request Bundle in the Microservice API Patterns. While the pattern idea is relatively simple, the implementation is a bit strange at first because no service protocol that I know of (CORBA, SOAP, REST, HTTP, gRPC, ...) supports this natively. This means that the built-in ways to signal back errors are not working (e.g., HTTP status codes are for the whole response and not for a part) and need to be moved from the protocol level to the payload level. I think that this is the reason that many developers and service/API designers do not use this approach because it feels wrong to them.
I encountered this pattern often in my past and it is very beneficial: It reduces the number of concurrent requests, it eliminates the need for a thread pool on the client side and it clearly assigns the responsibility of request parallelization to the provider side where it belongs. For a more detailed explanation of the pattern please follow the link above to the pattern's description. If you want some more ideas on how to convey error information, there is also an Error Report pattern, which you can use with both "normal" services and Request Bundle services.
Example
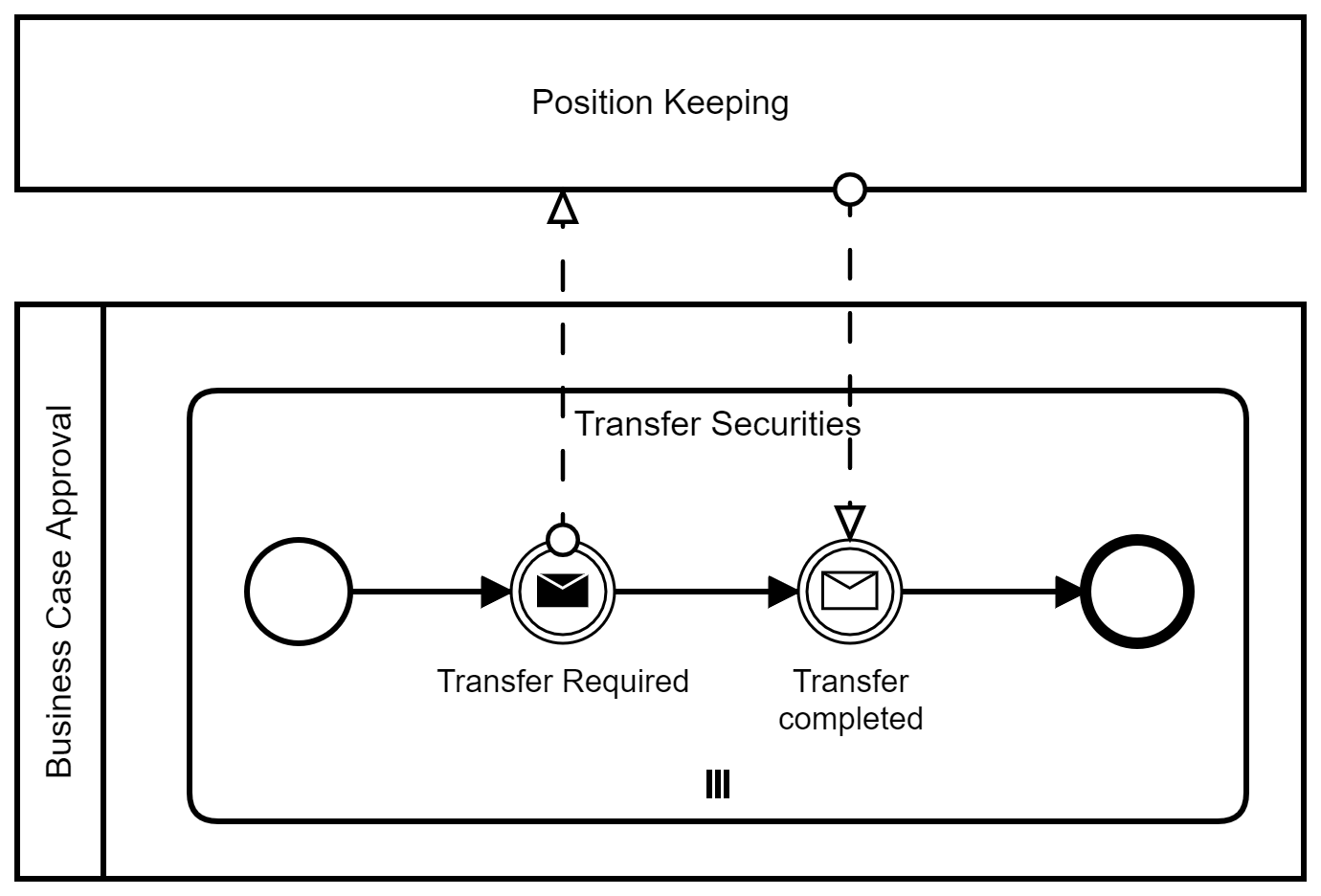
What does this mean for the message interaction part of the example process' old version as shown above? The whole subprocess "Transfer Securities" only exists to parallelize the transfer of securities in the Position Keeping service. If we change the called operation by using the Request Bundle pattern, we can eliminate the whole subprocess and move the message sending and reception onto the top-level of the process. However, we also need to take care of the option that no transfer is necessary because this is not implicitely handled by the multi-instance subprocess:
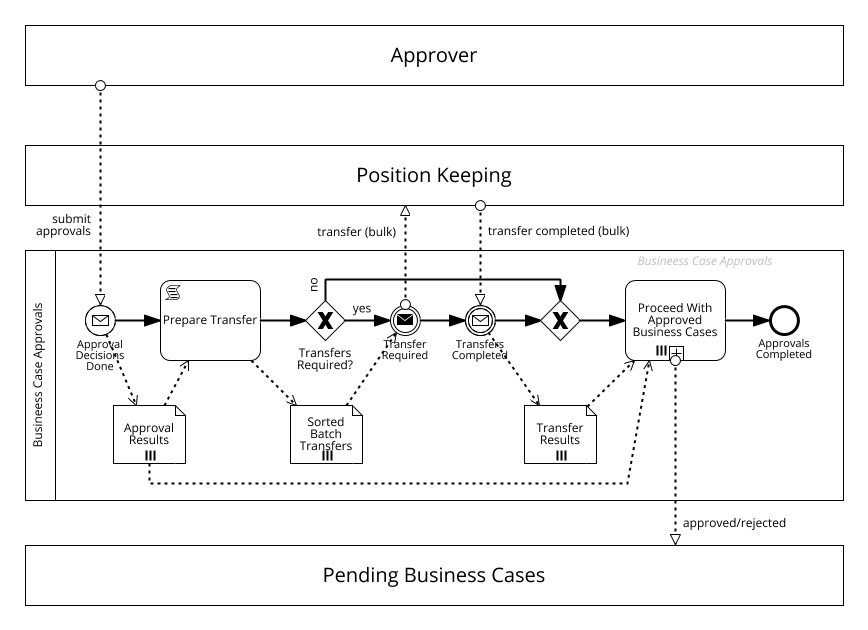
This will also make our code much shorter. We can eliminate the subprocess class and all parallelization code and move the message handling up to the main process:
public class ApproverProcess {
private static final ExecutorService APPROVER_PROCESS_EXECUTOR = Executors.newFixedThreadPool(10);
private PositionKeepingService positionKeeping;
private CountDownLatch messageLatch = new CountDownLatch(1);
private TransferCompletedMessage message;
public void approvalDecisionsDone(List<ApprovalResult> approvalResults) {
List<BatchTransfer> sortedBatchTransfers = prepareTransfers(approvalResults);
transferSecurities(sortedBatchTransfers);
proceedWithApprovedBusinessCases(approvalResults, sortedBatchTransfers);
}
private List<BatchTransfer> prepareTransfers(List<ApprovalResult> approvalResults) {
return null;
}
private void transferSecurities(List<BatchTransfer> sortedBatchTransfers) {
List<TransferSecuritiesProcess> subprocesses = new ArrayList<>();
for(BatchTransfer bt : sortedBatchTransfers) {
subprocesses.add(new TransferSecuritiesProcess(bt));
}
try {
APPROVER_PROCESS_EXECUTOR.invokeAll(subprocesses);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
if(!sortedBatchTransfers.isEmpty()) {
positionKeeping.transferBulk(sortedBatchTransfers);
waitForTransfersCompleted();
}
}
private TransferCompletedMessage waitForTransfersCompleted() throws InterruptedException {
messageLatch.await();
return this.message;
}
public void messageReceived(TransferCompletedMessage message) {
this.message = message;
messageLatch.countDown();
}
private void proceedWithApprovedBusinessCases(List<ApprovalResult> approvalResults,
List<BatchTransfer> sortedBatchTransfers) {
}
}
class TransferSecuritiesProcess implements Callable<Void> {
private BatchTransfer batchTransfer;
private PositionKeepingService positionKeeping;
private CountDownLatch messageLatch = new CountDownLatch(1);
private TransferCompletedMessage message;
public TransferSecuritiesProcess(BatchTransfer bt) {
this.batchTransfer = bt;
}
@Override
public Void call() throws Exception {
positionKeeping.transferBulk(batchTransfer);
TransferCompletedMessage message = waitForTransferCompleted();
// we can now deal with message
return null;
}
private TransferCompletedMessage waitForTransferCompleted() throws InterruptedException {
messageLatch.await();
return this.message;
}
public void messageReceived(TransferCompletedMessage message) {
this.message = message;
messageLatch.countDown();
}
}
As you can see this simplifies the logic on the client side considerably. But wait? Doesn't the provider now need to deal with this? The answer is yes but we have some advantages of this: The provider knows better how to parallelize subrequests. It can also decide dynamically whether it is worthwhile to do so. And more importantly: Sometimes the different requests can be put together and optimized in a single go (e.g., a larger data base query which is more efficient than multiple smaller queries). In other words: The provider can now handle and optimize the parallelization code in a single spot. Moreover, there are usually more clients than providers. Indeed, most often you have one provider and many clients. By moving the logic from the client side to the provider side you relief the clients from duplicating such logic over and over again (even if not all clients need it).
In most circumstances - like in this example - the use of the Request Bundle is superior to making many small calls. The interesting thing is that with well-modelled BPMN diagrams we can spot such opportunities for optimization rather easily. Every developer should know that it is a bad idea to call remote services in a loop but on the source code level it is often hard to tell because we use some service abstractions and all what is left is a method call in our business logic code. This behavior is made explicit by modeling, e.g., with BPMN.
We have now optimized our systems integration by using the Request Bundle pattern and thereby seeing a considerable reduction of complexity on the process/client side. In the next part of this series I want to discuss the problem of possibly hanging threads and how to approach this.
If you found this article interesting and you do not want to miss following episodes and other articles, please consider subscribing for article updates below - do not miss any interesting content!
After subscribing, please feel free to read the fifth part.