
Many developers don't like to concern themselves with the business side of their applications. Quite frequently I see that the whole business context, including business goals and business processes, is neglected, not understood, and not cared about. Inevitably, this results in un-reasonable software. However, modeling business processes first as part of the requirements analysis and then transferring them into software (code) can make your source code better structured and easier to understand. Let us dive into why this is the case.
Recently, I have encountered an already existing but simple implementation of a business process that had to be changed and improved. The code base was messy and frequently questions for business requirements emerged to which the answers already had to be in the existing code base. Moreover, the code was unreliable and took never-ending fix-deploy-test cycles to get it working somehow. This was especially the case with parallel code, even more so when the process was split into several parallel branches and had to join.
As to be expected, there were several problems: Inconsistent abstraction levels of methods, no use of business terminology in identifiers, and non-suitable programming constructs for parallel processing amongst others.
But how can business process modeling help in this scenario? Because it let developers focus on a non-development artefact first. This is in contrast to other notations, like block-diagrams, data-flow diagrams, and UML diagrams, which developers use and commonly directly fall back to technical details and identifiers. That is also possible with business processes, of course, but it is less likely to happen. When in doubt, just ask yourself - or even better a business representative - whether he/she understands the process model and whether the names are “business language.”
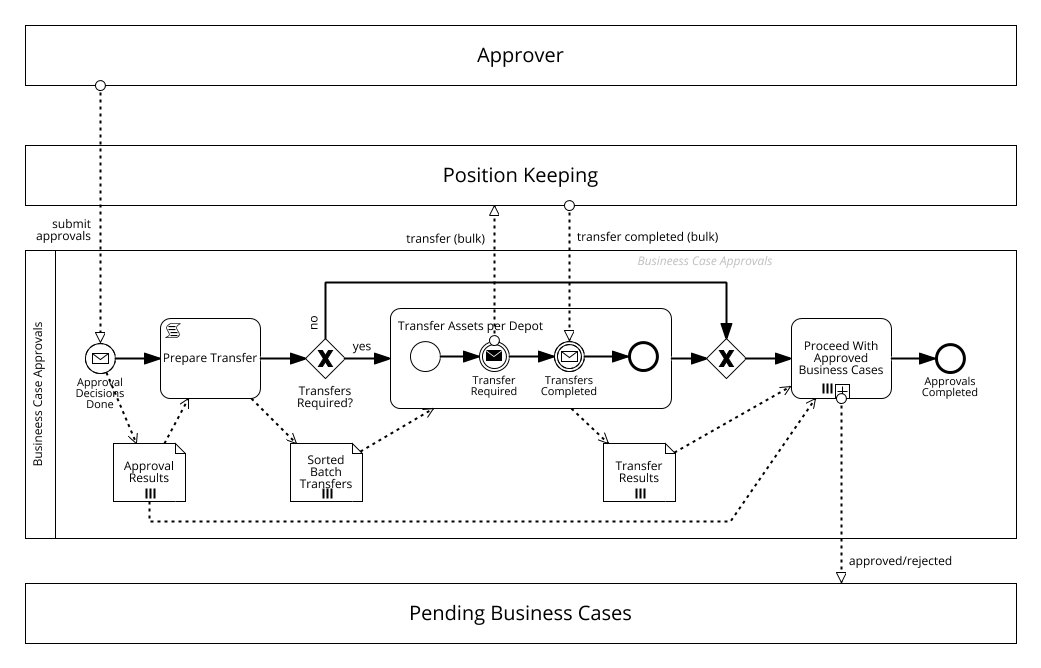
So let's have a look at the process above. It describes actions to be taken after an approver has approved or rejected some business cases. In some cases, business cases require a transfer of assets from one depot to another, which is handled by a position keeping service. The position keeping service is to be called with “move those assets from depot X to depot Y.” Due to this limitation not all transfers can be scheduled at once but need to be broken down in individual transfers in which all assets belong to one depot constellation.
If you are unsure about what the symbols with the three lines at the bottom of some activities and data objects mean, you probably find my previous blog post helpful, which explains the meaning and usefulness of these “multi-instance” markers for analysis and architecture.
We will discuss restrictions and design options for different characteristics of business processes in a later part. For now we just take this process, which requires no recoverability and is short-lived. A small first implementation step is to translate the process directly, i.e., verbatim, to a (Java) method:
public class ApproverProcess {
public void approvalDecisionsDone(List<ApprovalResult> approvalResults) {
List<BatchTransfer> sortedBatchTransfers = prepareTransfers(approvalResults);
transferSecurities(sortedBatchTransfers);
proceedWithApprovedBusinessCases(approvalResults, sortedBatchTransfers);
}
private List<BatchTransfer> prepareTransfers(List<ApprovalResult> approvalResults) {}
private void transferSecurities(List<BatchTransfer> sortedBatchTransfers) {}
private void proceedWithApprovedBusinessCases(List<ApprovalResult> approvalResults,
List<BatchTransfer> sortedBatchTransfers) {
}
}
What happened? There are several nice things happening right now without the need to invest much effort and thought:
- We have a class that encapsulates all process-related knowledge regarding the approver process. Perhaps we split this class into smaller classes later; but then we still have a package (or module or microservice) that naturally encapsulates this knowledge.
-
The method
approvalDecisionsDonenaturally uses business terminology only. This means that a) there is a method on the business-level abstraction and b) that this method is not encumbered with technical code. -
By looking at the
approvalDecisionsDonemethod we can clearly see the process flow without looking at other documentation. Checking for differences between (updated) business process models and our implementation becomes easy at once. - Our code has become modular and the newly created private methods for handling process steps are usually well cut and also have a) a good name (if the business process was modeled well) and b) have a designated responsibility for implementation.
- The newly introduced private methods have a lower abstraction level. Developers need to take care from here on to have methods on a single abstraction level. The deeper methods are in the call hierarchy, the more technical they get.
-
We have eliminated any messaging code from our class and therefore decoupled API concerns from our process-flow.
The
approvalDecisionDonemethod must be called by some endpoint implementation (be it REST, messaging, event, SOAP or something else). - An endpoint implementation (which is not shown here) also has a distinct responsibility: Transform the received data into internal, clean, and API independent domain objects and call our process implementation.
- Interestingly, this code is very similar to the level achieved by Robert C. Martin in his book “Clean Code” which I can only recommend. If you wondered how you can derive such clean code, this is one way to do it.
You might have noticed that the subprocess “Transfer Securities” has been implemented in its own method. Because the modeler of the business process thought that this it was a good decision and also took the effort to name it, it seems reasonable to profit from such logical boundaries in our code, too! This method must now contain the process-flow logic to make calls and wait for the corresponding asynchronous response. If you wonder how to do that, stay tuned for the second part of this article series. Please consider to subscribe to blog notifications below so that you don't miss it!
After subscribing, please feel free to read the second part.
|
<<< Previous Blog Post How Process Modeling can help you write better structured code (part 2) - Parallelism |
Next Blog Post >>> How to implement Pagination properly |