
Welcome to the second part of our implementation series of a BPMN model in (Java) code. Yes, no workflow engine, just a demonstration how your source code will improve if you directly reflect the business domain and its processes. Our main objective to still have easily comprehensible and well-structured code. But be aware that this series' example is concerned with a short-lived process without recoverability.
If you haven't read the first part, please read it first.
What is Fork-Join and why is it important?
After the end of part 1 I promised that we will look at the implementation of the subprocess. Before we do that, I'd like to discuss some background first, which will hopefully help you in your projects if you do not already know it. Parallelism is an important aspect of modeling business processes: Like with software, parallel execution helps to improve the performance of a business process, i.e., it reduces its mean execution duration.q
From a busines process perspective, a fork-join is the combination of two elements: a parallel split followed by a synchronization (for a more technical and theoretical description of these patterns you can look at the workflow patterns). However, there is also a closely related alternative: multi-instantiation of activities, which are then executed in parallel. Let's have a look at those concepts in the context of BPMN.
Fork-Join in BPMN
Parallel Gateway
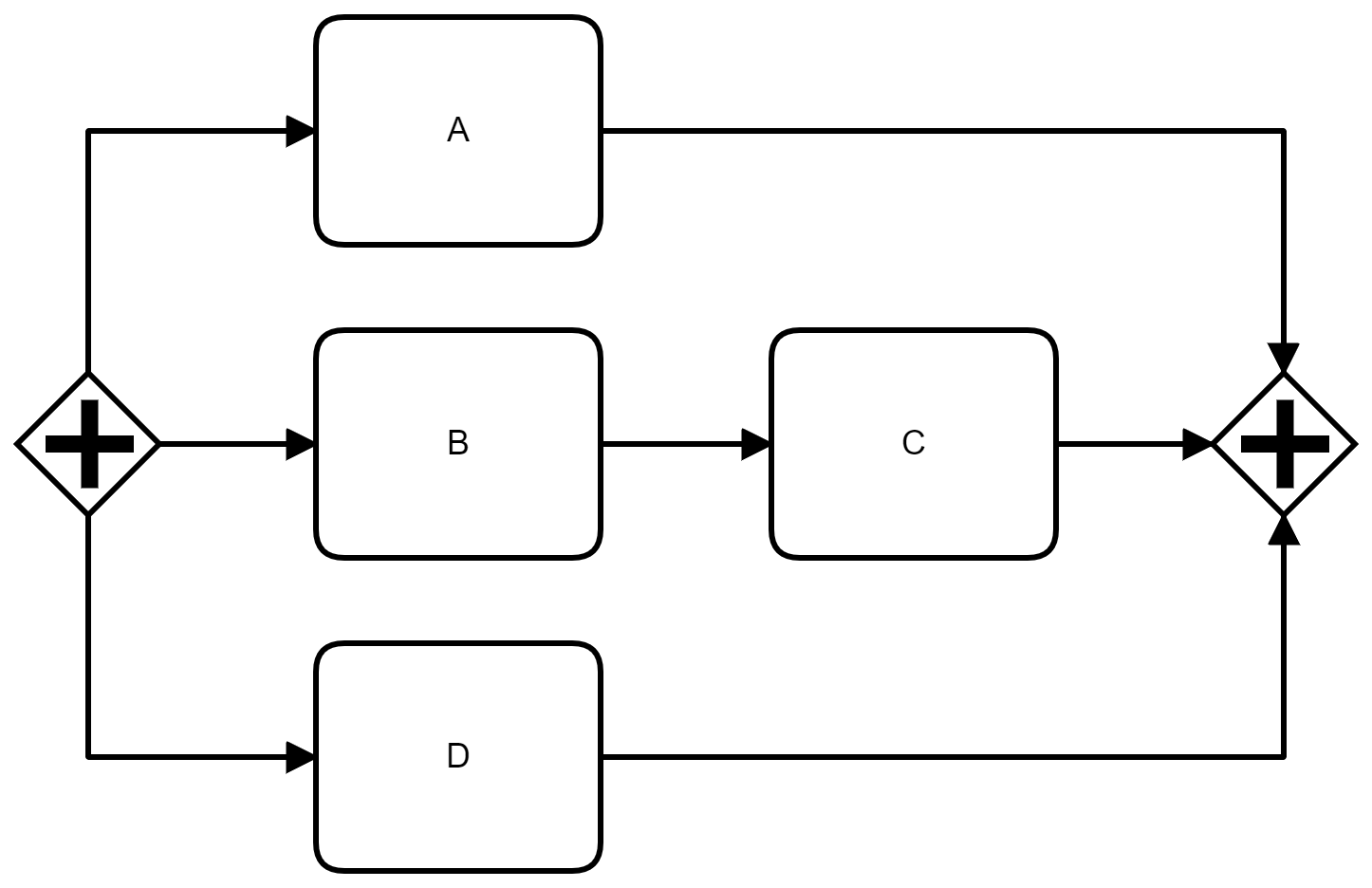
The diagram above shows a cleanly-structured BPMN model with a parallel gateway on the left, which splits the control-flow into parallel flows, and a parallel gateway on the right, which joins the control-flow back again. Activities following after the right parallel gateway will only be executed if all parallel branches have been completed. Parallelism in BPMN is defined as a concept: It just means that the branches can be executed in any order and possibly in parallel. As such, following execution orders are all valid according to this model (but there many more possibilities):
- A, B, C, D
- A, B, D, C
- D, B, A, C
- ...
The only constraint in this example is that C can only be executed after B is completed and every activity is executed exactly once.
Multi-Instance Activity
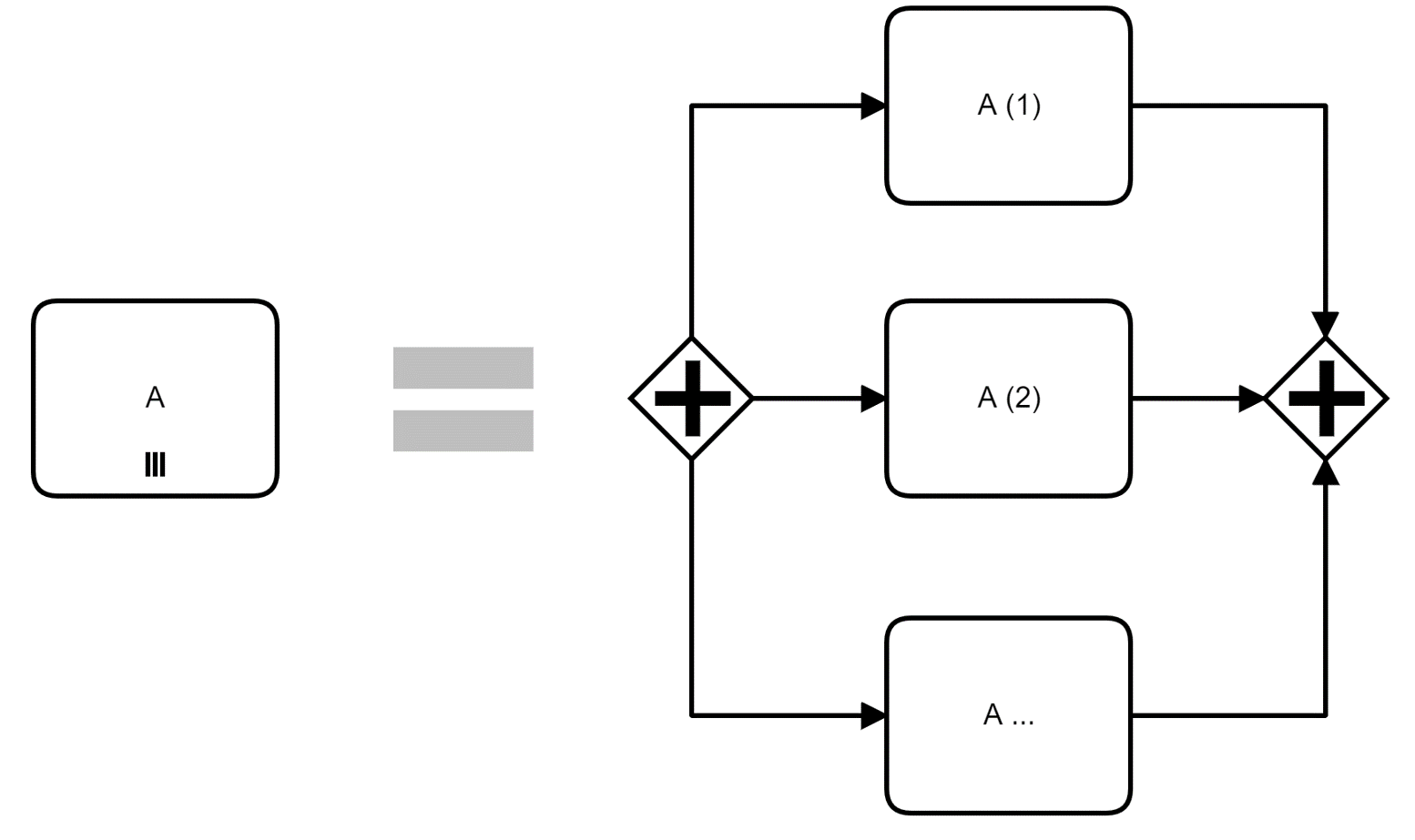
However, parallelism is also possible with multi-instantiation as shown in the diagram above: The multi-instance marker at the bottom of any activity indicates that the activity will be executed in parallel n number of times. n can be determined at run-time or design-time, although this is handled via properties that are not depicted on the diagram. Usually, a list data object is connected to indicate that the activity is executed for each element of this list. This mechanism is used in our approver process example below.
Multi-Instance Subprocess
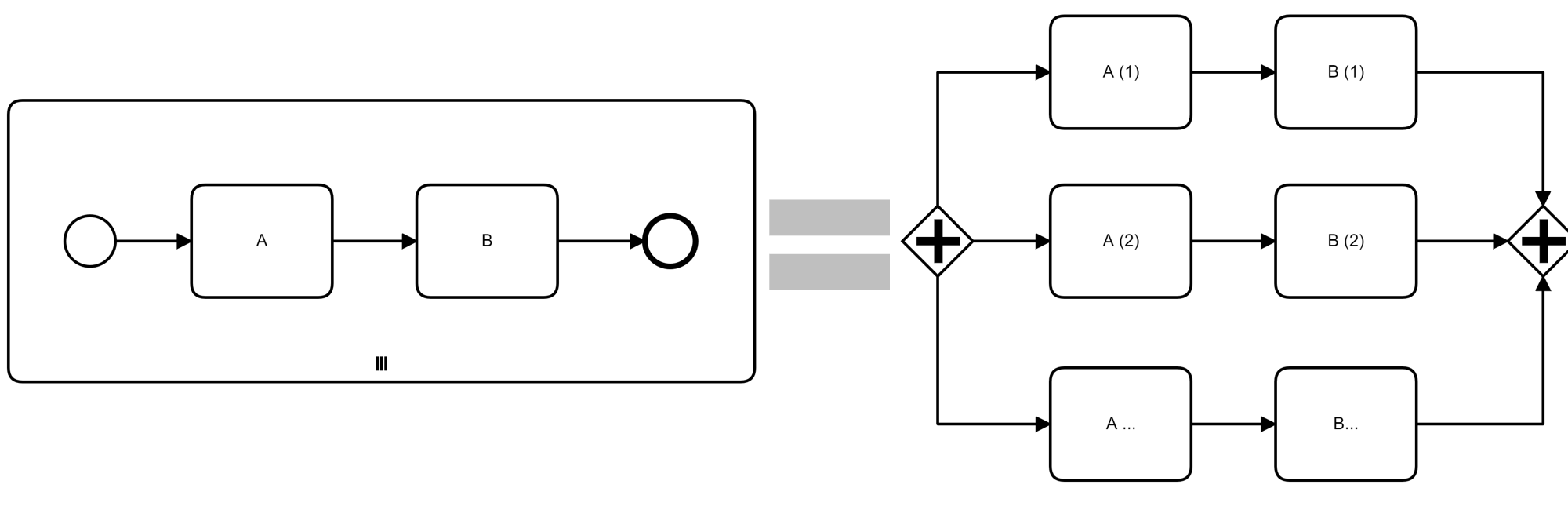
Because a subprocess is also an activity from BPMN's metamodel point of view, a subprocess can be multi-instance, too. This is also the more common case. In the diagram above tasks A and B are contained within a multi-instance subprocess. This is equivalent to a parallel split with n branches, which can be determined at run-time and need not to be modelled at design-time.
Example: Dealing with the Multi-Instance Sub-Process
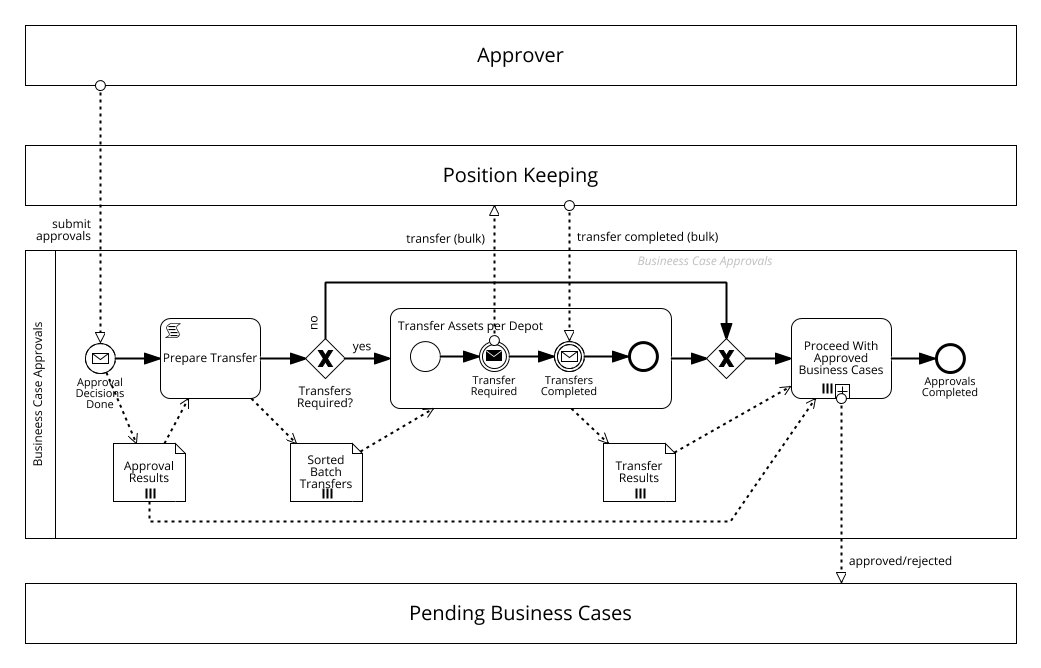
Let's now come back to our example approval process.
This process contains a multi-instance subprocess called “Transfer Securities.”
We now need to implement this subprocess in our Java program with the intent to keep the process-flow easily recognizable by our fellow team members and our future self.
We can use an Executor to invoke Callabless.
The nice thing about the Executor.executeAll method is that it already implements the synchronization for us:
The method will return, if all Callabless are completed (or have failed.)
However, from where do we get our Callable? We will extract the subprocess contents into a new class, which implements the Callable interface.
In our example, we need only one class because in a mulit-instance subprocess all branches are the same.
Alternatively, if a parallel gateway was used with different branches, each branch would require a own class.
In any case, I would think about defining the Callables inside the process class to group things together.
If the code gets too large, it is obviously possible to factor out the Callbables to standalone subprocess classes.
Our Updated Code Example
With this information and guideline, we extend our example code from part 1. Already existing code from part 1 is faded out to make the additions better visible:
public class ApproverProcess {
private static final ExecutorService APPROVER_PROCESS_EXECUTOR = Executors.newFixedThreadPool(10);
public void approvalDecisionsDone(List<ApprovalResult> approvalResults) {
List<BatchTransfer> sortedBatchTransfers = prepareTransfers(approvalResults);
List<TransferResult> transferResults = transferSecurities(sortedBatchTransfers);
proceedWithApprovedBusinessCases(approvalResults, transferResults);
}
private List<BatchTransfer> prepareTransfers(List<ApprovalResult> approvalResults) {}
private List<TransferResult> transferSecurities(List<BatchTransfer> sortedBatchTransfers) {
ListLet's walk through the extensions made:
-
Line 3 declares an
Executorto be used for processing the parallel portions of our process-logic. Obviously, this declaration is the most simplicist. Of course an executor can also be injected by a Spring config or something else. However, there are more important questions. Depending on the requirements and expected load, it can make sense to have a sharedExecutorfor all processes, to be able to configure the total parallelism in the application. If it is critical that all branches are really executed in parallel, it might be necessary to have anExecutorfor each process instance, i.e., it would become a local variable in thetransferSecuritiesmethod. Obviously the number of available threads is also an important decision. As a last decision, anExecutorimplementation must be chosen. It can be a simpleExecutorlike in this example or aForkJoinPoolor something else - always depending on your requirements. -
We added an implementation for the
transferSecuritiesmethod in line 13. It will instantiate a subprocess for eachBatchTransferobject. Afterwards the list of subprocesses is executed by calling theinvokeAll()method on theExecutor. This method will only return if all subprocesses have been finished. -
The subprocess is implemented as a
Callablein line 32. The subprocess manages its own data (batchTransfer) and has service stubs, which would likely be injected (positionKeeping). Thecall()method implements the subprocess logic. At the moment only a service call to initiate the booking is added; we will be looking at the response message in the next part of this series. If data needs to be passed back to the calling main process, this can be achieved by parameterizing theCalltemplate not withvoidbut with some response object.
Summary and Outlook
We are working towards a simple, easy, and understandable implementation of a short running business process in Java. So far, we accomplished this by having two methods that directly reflect the business flow of the main process and its sub process. We have other methods, which are called from those, which contain more technical code. This way, each method resided on a single abstraction level and the code gets easy to read and easy to change.
In the next part of this series, we will introduce the callback from the position keeping service to our subprocess. Will we be able to hold our process logic in a central place? If you are interested, please subscribe to the blog notifications below so that you don't miss the new article when it is published!
After subscribing, please feel free to read the third part.