
When naming ID references in attributes or database columns, a simple but crucial mistake is made very often. Explore with me what the simple mistake is, which has cost many projects thousands of dollars (or equivalent).
References vs. Values
There's a distinct difference between saving IDs or the values themselves. We've known this for decades when dealing with database designs: either you have an entity which you reference by ID, or you have a value column that stores, for instance, names. We also have this distinction in API design (see Data Element and Id Element patterns). There are different non-functional properties of these two designs, which include, but are not limited to, required storage space, data, consistency, and data access performance. It is crucial for developers to differentiate between and understand these two designs. Unfortunately, there can be fatal misunderstandings: If an attribute is actually an ID, but it's treated as a full data entry (for example a string) or vice versa. In many projects, over and over again, bad naming has led to mistakes in this area where developers unknowingly confuse ID references and values. To make matters worse such mistakes are usually found late in integration phases and thus cost a lot of money and require rework and possibly even design changes to the system. As such naming ID references is one of the crucial things to do right. And fortunately it's very easy!
Example
Let's look at one real-world example, where it unfortunately went wrong and led to problems later on.
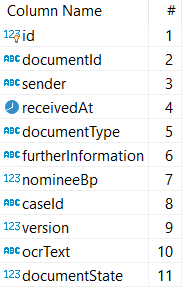
The attributes are part of a document table that stores meta data about a document: It has an ID entry, which is a technical ID. It has a document ID, which references a digital archive (this name can probably improved). We have a sender, we have information about the document type, the OCR text, and so on. Everything easy and straight-forward, isn't it?
If we look at the sender column more closely this looks innocent, but it isn't.
Let's look at the type next.
Perhaps this gives us more information.
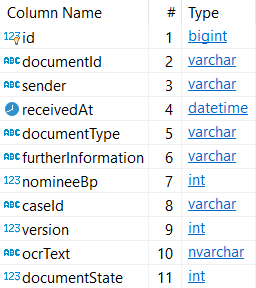
We see in the database it's a varchar and for any entities and normal programming languages, this would be mapped to a string.
This is crucial because the mapping to programming languages will remove all length information because most do not support strings with a maximum length.
This in turn means that this is the information of the data model as it is seen most often by developers.
They don't look at the DDL for the database table, but they look at the code and their business objects.
The varchar/string definitely suggests sender is a value because most IDs are numbers or UUIDs.
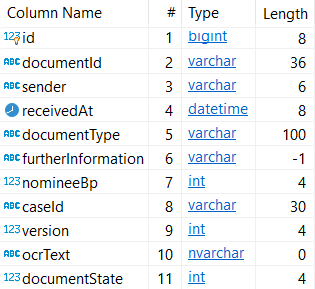
Only if we look further at the database type we see that this column is only six characters long:
The sender probably isn't the full name of the sender but it's a reference to something!!!
The problem is that this reference masks itself as a value due to its name - and this frequently leads to problems as it did in this project:
Later a developer assumed for an extension that this attribute stores the sender as a free text field, but it does not;
it unfortunately doesn't even have a foreign key relationship to another entity because of some other constraints and problems with the data model.
So there's no way to see what the contents of this column should be - except for looking at the length of this column (or any other additional documentation.)
Better naming convention
So how do we make this name better and less prone to misunderstandings? The first step is to really putID (or Id) as a suffix to every ID reference.
So senderId would make it next to impossible to mistake this field for free text but instead would have clearly screamed at the developer that this is an ID.
Because it's neither the primary key nor a unique key, it must be a reference to something else.
Now the question is what that something else is.
A better name would include the type of the referenced object:
sender is the role of this object and the type would be a partner because it references a business partner.
This means senderPartnerId would have been an even better name, which is clear to anyone and guides developers to make the right choices.
This simple difference can save you tons of money, time and arguably unnecessary discussions in your project!
tl;dr
If you use ID references, name them $role$Type"Id" (e.g., senderPartnerId) to support fellow developers in understanding and using the model correctly and to avoid misunderstandings and confusion between values and IDs.
If you found this article interesting and you do not want to miss following episodes and other articles, please consider subscribing for article updates below - do not miss any interesting content!
|
<<< Previous Blog Post Interview with Eric Wild and Daniel Lübke about Microservice API Patterns |
Next Blog Post >>> Basics: Why you must limit permissions for your database user(s) |