
With this article I want to start a new series, in which I will irregularly write about research results that in my point of view are interesting to practitioners.
I see research as a tool of learning: I like to reserve a day of the week for research. It is a mixture between educating myself and tackling conceptually interesting problems. I can use this day to address problems for which there is no time in projects but which are nonetheless important and compare techniques to one another. Projects can so much benefit from this and there are many interesting research articles out there, which are out of sight of practitioners. Perhaps you can also use the presented information in your discussions to persuade others to do the right thing. For example, with the findings shortly explained in this article, I have been able to make better informed decisions as an architect in my software projects!
I will start with some of my own research articles although I plan to add articles about results from other researchers. The goal in both cases is to present interesting findings to the community of practitioners together with my interpretation and my thoughts.
This article will discuss a study which I did together with Tobias Unger and Daniel Wutke back in 2018: We analyzed three different business process-oriented projects with 184 BPEL processes with regards to their process-flow and data-flow complexity. We found that data transformation logic is larger and more complex than the process logic. Read on to understand how we came to these results and what this means for software development!
Why is the data-flow dimension interesting?
If you have read books about business process design you have often read about how to model those using BPMN or other modeling languages. There are many ways of structuring the control-flow and the list of so-called workflow patterns, which can be modeled (e.g., parallel or sequential execution but also much more complex patterns), is huge. However, if you have been more concerned with integration architecture and actual integration work between complex software systems control-flow is usually not the problem - the mapping of data is. Thus, the interesting question when automating and digitizing business processes, i.e, their implementation in software, is where does complexity occur because as a software architect (and also as a software tester) you want to react to this complexity accordingly.
Why BPEL and not BPMN in this study?
We analyzed 3 projects built in BPEL and which use different process engines (ActiveVOS, Oracle BPM, and IBM Process Server). Now you might ask whether BPEL is outdated and why we still did research on BPEL processes anymore! The answer is simple. First of all, it is not easy to find projects willing to cooperate with research in order to gain insights and improve (if you are such project, please contact me!). Secondly, while BPMN is for sure the choice of technology to go for if you start a new project, BPEL has some attributes that make it still a worthwhile research object:
- The technical binding is well defined: You know how (SOAP) services are called and there is a standard and low-code way to do that. In contrast, the BPMN standard has no defined way for calling any service or logic in any technology; this is left to the vendor.
- There is a clear distinction between calling and offering services on the one hand and executing data transformations on the other hand : More importantly for this study, BPEL has a clear separation of logic between process and service invocation logic, which is completely model-driven, and the data-flow transformations (so-called assign activities), which can be defined by using XPath and XSLT (and vendors extensions).
As such it is feasible to distinguish data transformations and service invocation logic in BPEL and usually not in BPMN. In contrast, when using Camunda BPMN (and many other Java-based engines for that matter) a Java implementation is bound to a task, which usually contains both data mapping and service invocation logic, which is impossible to distinguish.
Still, we can transfer the knowledge gained via studying BPEL processes when using BPMN: This complexity is inherent to the problem and not to the technology used. As such, we will still have to map data at some point and need to define the process execution order somewhere regardless of which technology or architecture we want to use. We cannot get a software implementation that is less complex than the business requirements!
What we looked at
We developed extensions to an open source tool called BPELStats (available on GitHub) that calculates many metrics, including:
- Number of Source Code Lines for each Data Transformation Language (XPath, XSLT; XQuery, Java, BO Maps, XML Maps)
- Number of Conditions for each Data Transformation Language
- Number of Iterations for each Data Transformation Language
- McCabe Complexity for each Data Transformation Language
- Number of BPEL Basic Activities (a.k.a. statements)
- Number of BPEL Process-Flow Conditions
- Number of BPEL Process-Flow Iterations
Plain Results
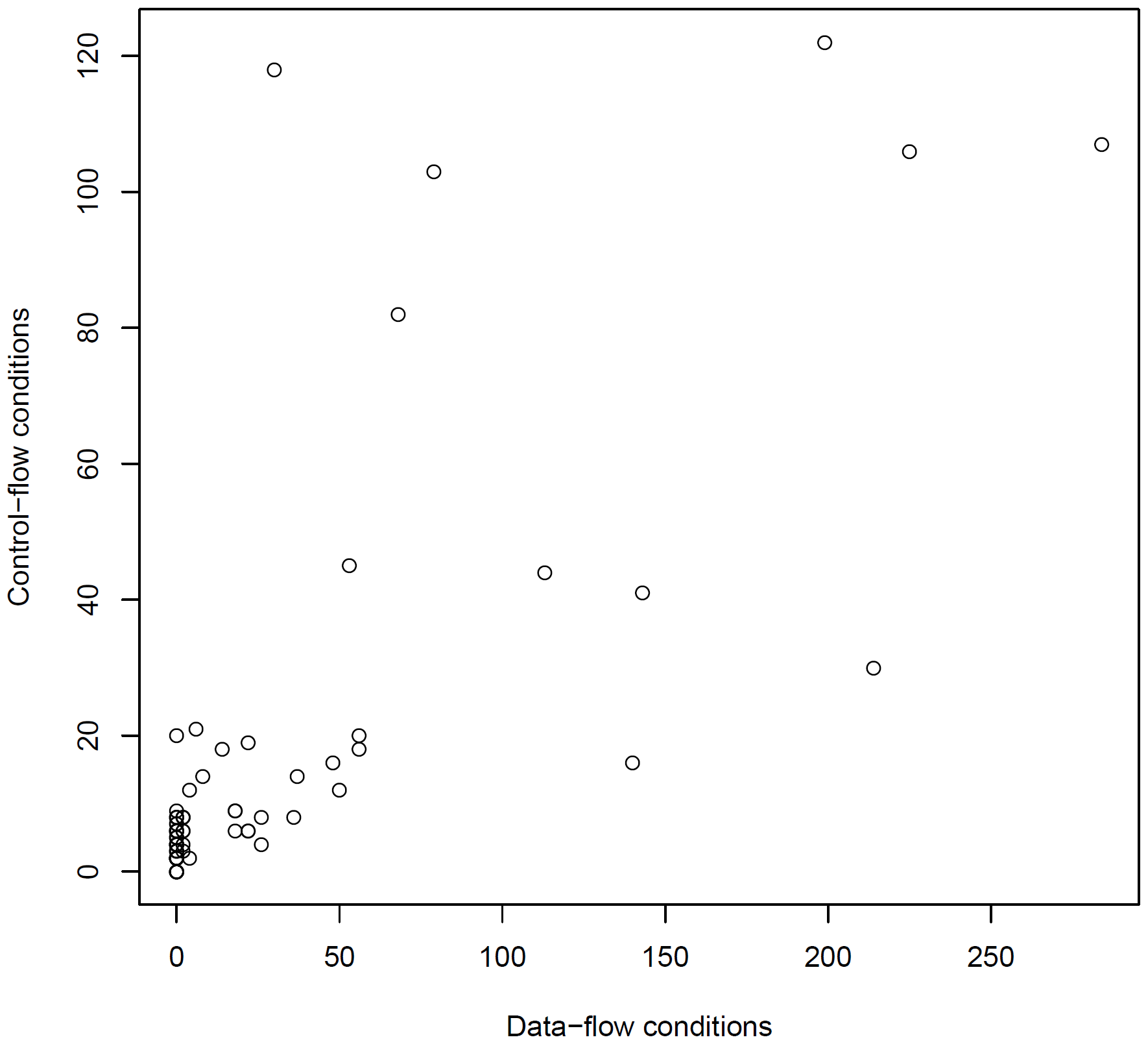
The study results show that data-transformation logic is larger and more complex than the process logic itself when implementing business processes. One of the comparisons between process-flow and data-flow is the number of decisions (e.g., if statements) is shown in the figure above, which is an aggregation of the data shown in the paper in figure 2. If we take a look at this figure, we can see that there are at least double the number of conditions in data-flow transformations than they are in the process-flow. We can also observe that the relationship seems to be approximately linear: the more decisions we have an either dimensions, the more we have on the other. However, We measured similar results for the number of iterations and lines of code (vs. basic activities in the process).
While the linear relationship was present in all three projects, the coefficients were different. We could not measure why this was the case. From my point of view, likely influencing factors as the language of the data transformation (XSLT, XQuery, Java, ...) and the differences in the data models of called services.
What to do with these results?
For software development teams this means that while understanding the business process is important, care must be taken of the data-level integration of systems and services required to fulfill the business goals. From an architectural point of view software architects probably want to isolate data transformation logic as much as possible (e.g., by using incoming and outgoing abstraction layers). Also testing requires more emphasis on playing with different allowed data constellations rather than trying to cover the process flow only. Unfortunately, test coverage metrics in that domain are heavily reliant on the process-flow dimension and neglect the data-flow dimension. The results here seem to indicate that this is not a sufficient metric to judge test coverage.
Short:
- The more systems you need to integrate, the more process activities you will have.
- The more activities you have in the process, the more data transformation code you will have.
- The data transformation code in your project will be an asset, which is technically hard to deal with.
- Incentivize your software architects to make your data transformations easy to change, easy to understand, and easy to test!
- Incentivize your testers to really cover as many data(!) constellations as possible!
While I am a strong advocate of business process modeling to make software teams better understand the requirements and their context, this does not mean that data transformation and data mapping requirements can be ignored. I think from a software architect point of view, there must be better guidelines on how to design data transformations: They must be easily testable, easy to comprehend, and probably easy to adapt to changing data structures in surrounding systems or even changing systems in the environment (e.g., ERP migrations).
As a side note: Vendors of orchestration systems, like BPMN engines and the like, often pitch their products with the promise of writing less code. While I really like those systems if they help me in my projects, this promise only holds for the process-flow dimension: They allow me to better develop with a business-oriented mindset and they certainly relief developers from dealing with lots of tricky problems like correct parallelization, compensation, and correlation. But in the end developers must still take care of all data-flow code! That is something to keep in mind!
Value of Simplicity and Cloud-based Orchestration
What can we do to reduce and limit the data-flow complexity? It seems that we need to simplify a) the business process and b) the system environments. I will concentrate on the latter here. For example, if you have multiple different ERP systems in use (e.g., due to mergers and acquisitions), you fail to consolidate those, and you require service consumers to call all of them, the required technical complexity to do simple tasks increases. And to be honest: In most organizations we have far too many systems with overlapping responsibilities - not only because of mergers and acquisitions but also due to internal politics. Each unnecessary system requires more or more complex tasks in business processes to achieve desired outcomes and thus will lead to larger data transformations and thus more technical complexity. This means it is more important than ever to reduce the number of different applications in use to stay agile and really bring digital transformation home!
Another question coming to my mind is: what is the real value of cloud-based orchestrators like Zapier? Is it really that you can point and click your business process together? We already could do this with BPEL many years back and with BPMN we have a much more powerful tool set! But these platforms offer adapters that handle the data input and output and thereby getting rid of writing data transformation code for supported systems. I think more and more that this is a hidden value and probably a larger one than the orchestration itself because it accelerates the development of executable business processes and reduces the threshold for people to orchestrate their systems and to automate their business processes. What do you think?
If you found this article interesting and you do not want to miss following episodes and other articles, please subscribe for article updates below - do not miss any interesting content!